Tentons un explication simple de l’Apprentissage Machine

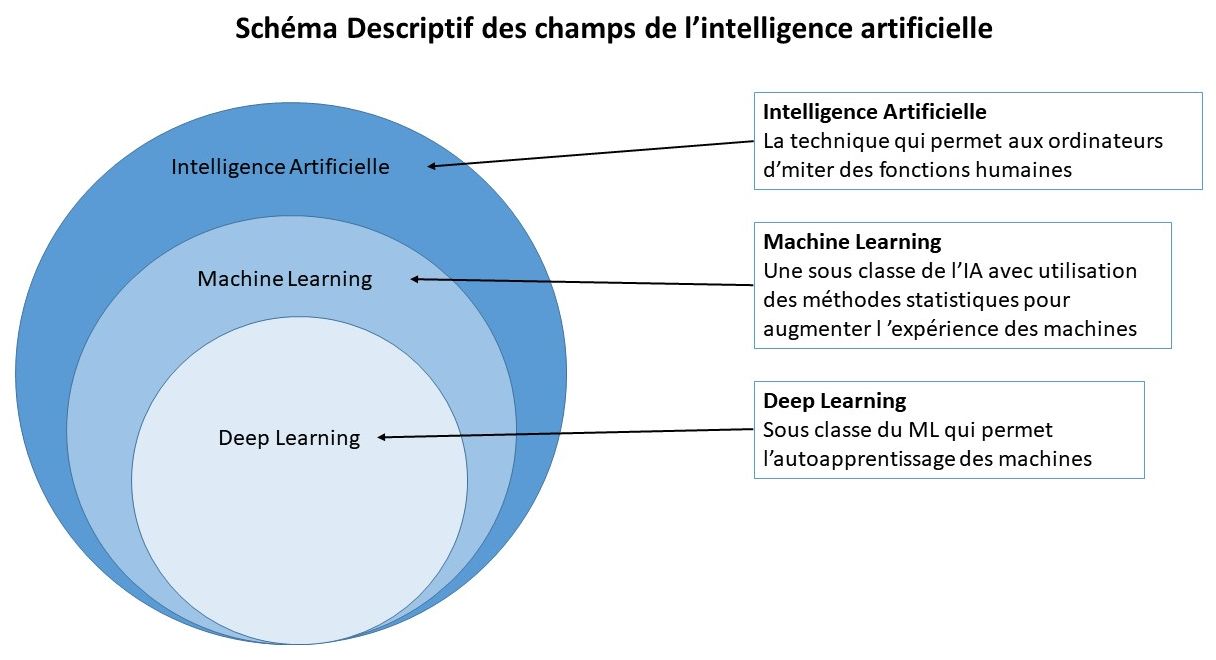
L’intelligence artificielle est la capacité d’un système informatique à imiter des fonctions cognitives humaines telles que l’apprentissage et la résolution des problèmes. Via l’intelligence artificielle, un système informatique utilise des mathématiques et une logique pour simuler le raisonnement des êtres humains afin d’apprendre de nouvelles informations et de prendre des décisions.
Même si le Machine Learning et l’IA sont très étroitement liés, ils ne sont pas identiques. Le Machine Learning est considéré comme un sous-ensemble d’intelligence artificielle.
Le Machine Learning est une application pour mettre en œuvre une IA. Ce processus consiste à utiliser des modèles mathématiques de données pour aider un ordinateur à apprendre sans instruction directe. Ainsi, un système informatique continue à apprendre et à s’améliorer de manière autonome, en fonction de l’expérience.
Un ordinateur « intelligent » utilise l’intelligence artificielle pour tenter de penser comme un être humain et effectuer des tâches de manière autonome. Le Machine Learning est la manière dont un système informatique développe son intelligence.
L’une des méthodes permettant d’entraîner un ordinateur pour imiter un raisonnement humain consiste à utiliser un réseau neuronal, qui est une série d’algorithmes modélisés d’après le cerveau humain. Le réseau neuronal aide le système informatique à développer une intelligence artificielle via l’apprentissage profond. C’est ce lien étroit qui permet à l’IA et au Machine Learning de fonctionner ensemble.
Nous allons donc parler du Machine Learning ou Apprentissage Machine
Les intelligences artificielles basées sur des modèles de machine learning vont sans aucun doute être de plus en plus au service de la santé, mais peut-on réellement leur accorder une confiance aveugle ?
Les intelligences artificielles basées sur des modèles de machine learning vont sans aucun doute être de plus en plus au service de la santé, mais peut-on réellement leur accorder une confiance aveugle ?
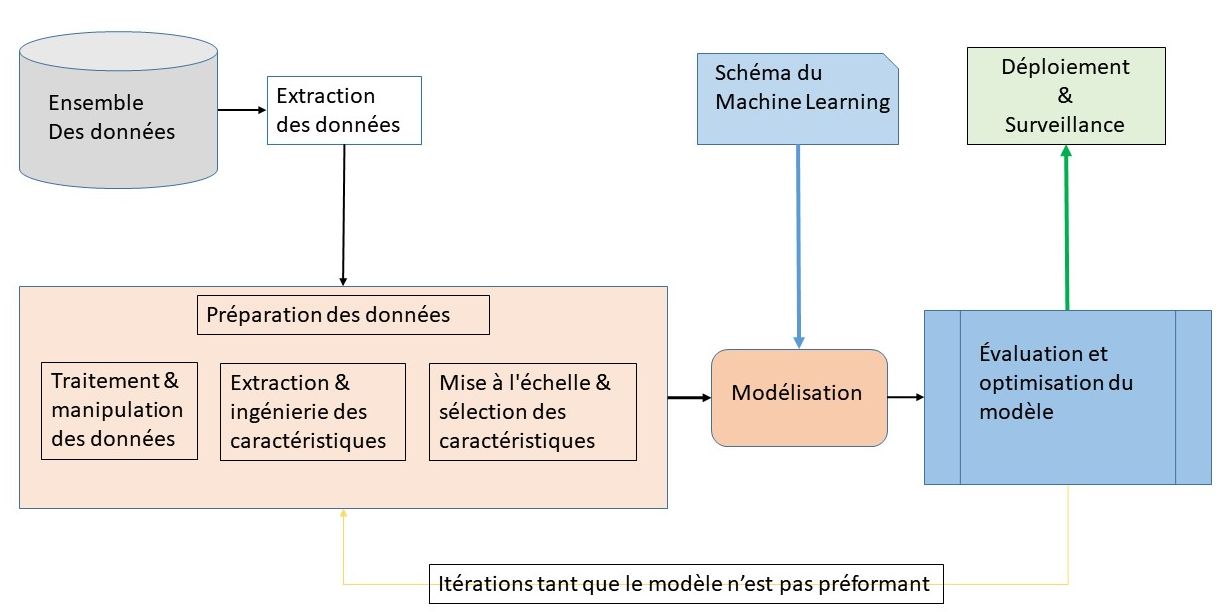
Un modèle de machine learning apprend des données qu’on lui fournit. Afin d’éviter d’obtenir des résultats biaisés, il est primordial de lui fournir des données les plus diversifiées possible. Pour illustrer avec un exemple, lors du développement d’une intelligence artificielle spécialisée dans la reconnaissance vocale, si les données fournies ne contiennent que des enregistrements de voix françaises adultes avec un accent neutre, l’IA ne sera pas capable de comprendre correctement des voix d’enfant ou avec accent.
Une des préoccupations majeures autour du modèle de machines learning dans la santé est le manque de transparence autour du fonctionnement d’apprentissage de l’algorithme…
Mes modèles de machine learning se nourrissent de données collectées en amont. Lors de l’émergence d’un nouveau virus, aucune donnée n’est disponible au préalable, nous devons alors compter sur le corps médical pour les collecter. Ainsi, il faudra du temps avant que modèle de machine learning ait assez de données pour pouvoir apprendre et avoir des résultats fiables…
Même si tout n’est pas parfait et que de nombreux obstacles sont à surmonter, l’utilisation du machine learning dans la médecine fait et continue de faire beaucoup de progrès. En ayant un objectif coopératif entre l’IA et les médecins, celle-ci contribuera à l’amélioration des systèmes de santé. De la détection précoce de cancer, à des recommandations de traitement personnalisé, tout en passant par l’anticipation d’épidémies, les intelligences artificielles dans le domaine médical sont promises à un bel avenir.
NDLR : cet article a aussi sa place dans la page IA dans la Santé.
L’article complet : Machine learning, ami ou ennemi de la médecine ?
Publié sur le JDN le 18 janvier 2021 par Etienne Du Portal

Au delà des biais, il convient de réfléchir à la structuration des données pour algorithme d’apprentissage.
La gestion du contenu et des données est un défi pour de nombreux processus métier et tout particulièrement dans notre cas. La capacité d’organiser une hétérogénéité des matériaux numériques afin que les ordinateurs puissent facilement traiter les informations permet de faire face à la vague croissante de méga-données et d’en extraire la valeur de l’information.
Généralement les données non structurées ne sont pas analysées dans la plupart des entreprises !. Et des informations précieuses sont perdues, à moins que vous n’utilisiez beaucoup de temps et de personnel pour extraire, traiter et classer.
Pour cette raison, les entreprises profitent des progrès de la gestion de contenu pour l’intelligence artificielle. En particulier, le développement de l’apprentissage automatique et de l’intelligence artificielle permet la création de modèles dans l’information qui facilitent la diffusion de contenu pour le traitement de données, d’images et de vidéos, grâce à l’utilisation du langage naturel, de la reconnaissance vocale ou de la reconnaissance d’images, entre autres.
L’application de la technologie cognitive au contenu ne nécessite pas de changement de rythme immédiat. En fait, la gestion du contenu de l’intelligence artificielle peut être mise en œuvre via une série d’étapes. Plus une entreprise souhaite tirer de la valeur de son contenu, plus la technologie cognitive à appliquer est avancée mais rappelons que cela peut être effectué petit à petit. Pour cette raison, l’intelligence de contenu est un voyage que les entreprises doivent entreprendre pour augmenter la valeur du contenu au fil du temps et de manière itérative.
Le développement de compétences cognitives plus élevées conduit à une augmentation de valeur pour les entreprises qui peuvent gérer stratégiquement des problèmes commerciaux très difficiles et qui semblait,au départ, ingérable. Plus un service de gestion de contenu est intelligent, plus il peut assumer et résoudre des activités qui étaient auparavant gérées par les employés.
Diverses industries utilisent la gestion de contenu par intelligence artificielle pour extraire de la valeur des données non structurées. Par exemple, les processus d’achat de paiement liés à la gestion du crédit et la dette sont des domaines dans lesquels l’intelligence de contenu peut avoir un impact important (Voir : IA dans la banque et l’assurance). De nombreuses entreprises effectuant des achats ou même recevant des paiements sur la base de documents papier, le traitement est un processus qui requiert encore beaucoup de temps de main d’oeuvre.
Pour les entreprises comptant des centaines ou des milliers de fournisseurs, la gestion d’un grand nombre de factures papier nécessite beaucoup de ressources. En appliquant l’intelligence artificielle aux processus comptables, les entreprises peuvent créer des processus plus efficaces, précis et économiques (Voir : DDDDD). Grâce à la gestion du contenu de l’intelligence artificielle, les entreprises peuvent automatiquement développer des directives ou des directives de conformité et remplir et soumettre les autorisations nécessaires pour garantir que les règles et réglementations ne sont pas violées dans le respect du RGPD.
Les entreprises travaillent d’arrache-pied pour atteindre les objectifs de transformation numérique, combinant numérisation de l’information, collaboration, mobilité et intelligence pour aider les entreprises à tirer parti de l’économie des données. Sans intelligence de contenu, la transformation numérique n’est pas vraiment possible au moins d’accepter de perdre beaucoup de temps donc d’argent.
La combinaison de l’automatisation des processus et de l’intelligence de contenu grâce à l’intelligence artificielle permet d’automatiser les processus axés sur le contenu (ce qui compte vraiment), et aux entreprises d’utiliser les ressources humaines de manière plus efficace et constructive, en gérant les processus de supervision et de validation, en se consacrant à un travail de plus grande valeur.
Si les documents sources peuvent être très différents, les données qui sont pertinentes sont souvent les mêmes. Il s’agit d’adresses postales ou mail, de dates, de prix, de noms de personnes ou d’entreprises, ou toute autre information rendant possible l’identification. Outre le manque de standardisation, le fait que nous continuons à tout imprimer est aussi un problème. Malgré de nombreuses solutions comme la signature électronique ou le fait de pouvoir avoir accès à nos documents presque partout, nous sommes encore nombreux à les imprimer.
Procédons par étapes…
Afin d’extraire des données à partir d’un document de façon automatique il faudra qu’il soit dématérialisé. Il faut alors se poser de nombreuses questions : le document a t-il été numérisé et si oui, quelle est la qualité du scan ? S’il s’agit d’une carte d’identité, est-elle neuve ou usée, l’arrière plan est-il coloré, comporte-t-il des symboles ? Ce sont des élément qu’on ne peut connaître à l’avance, et les identifier déterminera la lisibilité du document.
L’étape consiste à mettre les données dans un format apte à l’intégration dans le système.
Intégration physique des données dans le système avec un contrôle systématique du résultat.


Les bases de données sont la réalité cachée de la Nouvelle économie. Elles sont au cœur de technologies comme le big data, cloud et intelligence artificielle. Dès lors, leur appréhension par le droit, et notamment par le droit de la propriété intellectuelle et ses principes applicables, constitue un enjeu essentiel car les données sont l’objet de toutes les convoitises. Cette chronique de Pascal Agosti, avocat associé au sein du Cabinet Caprioli & Associés, vient préciser les risques d’une extraction illicite d’une base de données mais aussi les conditions à remplir pour protéger les investissements qu’elle représente.
Article publié sur L’Usine Digitale le 2 mars 2021 est trop bon, je le reproduis en partie ci-dessous.
Des points sont un peu techniques ; mais cela montre l’importance du droit et de la propriété intellectuelles.
N’en déplaisent aux chantres du Data mining ou du Web scraping. Les données présentes sur le Web peuvent en effet être soumises à différentes législations ou encore aux conditions d’utilisation du site dont elles sont extraites. Et puisque tout Juriste repart du texte et qu’il est bon de relire des dispositions stratégiques, l’article L. 342-3 du Code de Propriété Intellectuelle énonce ainsi :
« Lorsqu’une base de données est mise à la disposition du public par le titulaire des droits, celui-ci ne peut interdire :
Toute clause contraire au 1° ci-dessus est nulle.
Les exceptions énumérées par le présent article ne peuvent porter atteinte à l’exploitation normale de la base de données ni causer un préjudice injustifié aux intérêts légitimes du producteur de la base. »
Traduction opérationnelle de l’article L. 342-3 du CPI
Le principe est donc d’interdire l’extraction d’une base de données, le fait de l’autoriser étant donc l’exception. Le jeu des nouveaux modèles commerciaux de nombreuses entreprises de la Nouvelle économie est donc de caractériser les exceptions évoquées dans le texte.
Comment définir une base de données à ce titre susceptible d’une protection au sens du Code de la propriété intellectuelle ? Comment caractériser une extraction substantielle ? Qu’imposent les conditions d’utilisation du site cible de l’extraction ? En répondant à ce triptyque, les sociétés qui entendent recourir à cette pratique pourront disposer d’un premier aperçu (mais un premier aperçu seulement) de sa licéité.
Tous les recueils de données ne sont pas des bases de données
Une base de données se définit au sens de l’article L.112-3 du CPI comme « un recueil d’œuvres, de données ou d’autres éléments indépendants, disposés de manière systématique ou méthodique, et individuellement accessibles par des moyens électroniques ou par tout autre moyen ». Le risque d’une telle définition est son caractère quasi systématique. En effet, tout fichier numérique pourrait constituer une base de données en tant que collection d’informations : pour éviter un dévoiement de l’objet de la protection essentiellement prévue pour les bases dites factuelles, il faudra circonscrire la notion aux produits dont la collecte et la structuration du corpus requièrent un investissement particulier ou sont orientées vers une consultation réservée aux utilisateurs finaux.
On qualifie d’extraction le « transfert permanent ou temporaire de la totalité ou d’une partie qualitativement ou quantitativement substantielle du contenu d’une base de données sur un autre support, par tout moyen et sous toute forme que ce soit » (art. L. 342-1 CPI ). La substantialité de l’extraction dépend donc d’une analyse fine de la jurisprudence correspondante. Par exemple, une décision de la Cour d’appel de Paris du 2 février 2021 vient déterminer les conditions de qualification d’une extraction qualitativement et quantitativement substantielle d’une base de données.
Ainsi, l’extraction de 35 % du contenu du site ne constitue pas une extraction quantitativement substantielle. Le caractère qualitativement substantiel de l’extraction est également refusé à défaut d’éléments précis relatifs au développement du domaine concerné ou des investissements s’y rapportant spécifiquement. Cependant, la pratique de l’aspiration en continu du site constitue une opération excédant manifestement les conditions d’utilisation normale qui interdisaient l’extraction de la base de données et son arrêt est ordonné.
La Cour précise « Les constatations effectuées à partir de 100 annonces immobilières des rubriques “locations” et “vacances” montrent que 96 d’entre elles reprennent toutes les informations des annonces du site de la société LBC, à l’exception du numéro de téléphone de l’annonceur, ces annonces mentionnant “contact-voir le numéro de téléphone », puis si l’on clique sur cet onglet “contact sur un site externe, cliquer pour accéder” ouvrant un nouvel onglet avec la page correspondante du site leboncoin.fr.
Les premiers juges ont retenu à tortqu’une telle indexation ne constituait pas une extraction au sens de l’article L.342-1 susvisé, alors que l’existence de ce lien hypertexte accessible après plusieurs clics n’est pas exclusif du transfert de la partie substantielle de l’annonce, toutes les données relatives au bien immobilier (localisation, surface, prix, description et photographie du bien) étant reproduites à l’exception du téléphone de l’annonceur, de sorte que ces constatations, relatives à des actes imputables à la société Entreparticuliers.com directement concurrente du producteur de la sous-base de données, outrepassant les droits légitimes de l’internaute et portant préjudice à l’investissement du producteur de la dite sous-base, caractérisent des extractions prohibées. »
Il ne s’agit que d’un exemple d’une jurisprudence désormais foisonnante tant la « propriété » de la donnée est devenue essentielle à de nombreux modèles commerciaux.
Afin de prouver une extraction substantielle par un tiers, plusieurs arrêts consacrent une analyse qui pourrait encourager les producteurs de base de données à introduire au sein de celles-ci des données « pièges » ou « sentinelles », c’est-à-dire d’insérer volontairement de fausses données identifiées comme telles, ne pouvant être présentes dans d’autres bases qu’à la suite d’une extraction sans vérification comme la décision du TGI de Paris du 13 avril 2010, Sté Optima on Line.
Les juges peuvent également prendre en considération la comparaison du temps de développement de la base concurrente par rapport à la base prétendue d’origine comme le propose la décision de la Cour d’appel de Paris, Pôle 5 – chambre 1, 27 juin 2012, n° 09/28753. Dès lors, il conviendra – tant pour un producteur de base de données qu’une entreprise dont le modèle commercial s’appuie sur l’extraction de données – de déterminer la licéité de leurs pratiques. Il en va de la rentabilité de leurs investissements.
Pascal Agosti, avocat associé, docteur en droit
Caprioli & Associés, société membre du réseau Jurisdéfi

l’apprentissage fédéré (en anglais : federated learning) est une méthode ou un paradigme qui consiste à entraîner un algorithme sur la machine des utilisateurs d’une application et à partager les apprentissages réalisés sur la machine de chaque utilisateur. Cette méthode s’oppose à l’apprentissage centralisé où l’apprentissage se fait sur les serveurs du fournisseur de service. Elle permet notamment un meilleur respect de la vie privée des utilisateurs.

L’apprentissage fédéré permet de passer de l’apprentissage centralisé à l’apprentissage au plus près des utilisateurs.

Source : Science Étonnante
Une vidéo journal « Le Monde »
Alors que les algorithmes devaient révolutionner nos vies, les belles promesses des géants de la tech sont-elles en passe d’être tenues ? Un état des lieux documenté des impasses auxquelles se heurte encore l’intelligence artificielle.
Il a fallu patienter jusqu’à l’aube des années 2000 pour que, avec l’essor exponentiel d’Internet, la science s’emballe et annonce une nouvelle ère. Grâce à la masse incommensurable de données numériques et à de savants programmes informatiques, l’homme allait enfin être libéré de toute une liste de servitudes et de malheurs. Depuis 2010, avec le coup d’accélérateur lié au deep learning – apprentissage profond, soit la capacité des machines à apprendre –, on allait toucher au but : les algorithmes aideraient les médecins à soigner les cancers ; les voitures rouleraient sans conducteur ; les robots épargneraient la vie des soldats. Mais qu’en est-il aujourd’hui ? Les belles promesses de géants de la tech sont-elles en passe d’être tenues ?
À l’heure du bilan d’étape, les avancées sont plus nuancées, à en croire les chercheurs de renommée mondiale réunis dans ce documentaire, comme Yoshua Bengio (prix Turing 2018), François Chollet (directeur informatique à Google) ou la lanceuse d’alerte américaine Meredith Whittaker. Car en fait de révolution technologique, l’IA patine. Derrière ses prouesses tant vantées, les seules intelligences à l’œuvre sont, pour l’heure, celles des humains qui travaillent dans l’ombre pour entraîner, corriger, voire suppléer les algorithmes. Ce qui n’empêche pas les « machines intelligentes » et les assistances automatisées, malgré leurs limites, de s’immiscer de plus en plus dans nos vies intimes et sociales. Sur un ton aussi irrévérencieux que pédagogique, recourant à l’animation ainsi qu’à de courts extraits de fiction cinéma ou de séries télé, Cécile Dumas et Jean-Christophe Ribot (L’aventure Rosetta – Aux origines de la vie) démystifient les sciences de l’informatique et invitent à réfléchir sur la délégation de nos décisions à des processus automatiques. Un état des lieux qui remet, intelligemment, les pendules à l’heure.

Particulièrement vulnérables, les applications dopées à l’IA ne sont pas toujours sécurisées comme il se doit. Des data sets au déploiement, il convient de protéger toute la chaine. Explications.
Comme c’est souvent le cas pour les technologies encore émergentes, les entreprises-sous estiment les enjeux de sécurité en matière d’intelligence artificielle. Y compris plus importantes d’entre-elles. Si 58% des sociétés du Cac 40 mentionnent le lancement de projets d’IA dans leur dernier rapport annuel, 2% seulement font le lien avec la cybersécurité, d’après une étude de Wavestone parue l’an dernier. « Pourtant, une application qui utilise du machine learning présente non seulement tous les risques classiques liés à une infrastructure IT et une application, mais hérite aussi d’autres risques », estime Carole Meziat, manager en cybersécurité chez Wavestone et coauteur d’un guide sur le sujet.
L’article complet (Réservé aux abonnés) : Comment sécuriser le machine learning
Les données d’apprentissage sont le carburant du machine learning.
De leur qualité dépendra la performance des résultats des modèles de machine learning. Depuis quelques années, les sites proposant des sets d’informations en open data utilisables pour l’apprentissage machine ont fleuri sur le web.
Data.gouv.fr regroupe une vingtaine de jeux de données open source conçus pour être directement exploitables par des algorithmes de machine learning. Catégorisés par typologie de modèle, ils recouvrent des domaines variés. Sur le terrain des régressions linéaires, on retrouve les demandes de valeurs foncières, un inventaire des gaz à effet de serre territorialisé, ou encore une cartographie des niveaux d’insertion professionnelle des diplômés de Master. Côté modèles de classification, on relève les données annuelles des accidents corporels de la circulation routière, les résultats des contrôles officiels sanitaires, ou encore des data sur l’orientation des toits dans l’Hexagone. Sur le front des séries temporelles se concentrent des informations relatives au Covid 19, notamment des données hospitalières et des indicateurs de suivi de l’épidémie.
Vous trouverez : 47 126 Jeux de données – 281 458 Fichiers –3 752 Réutilisations –115 472 Utilisateurs – 5 017 Organisations – 13 250 Discussions
Fondé en 1987 par David Aha, doctorant de l’Université d’Irvine en Californie, l’UCI Machine Learning Repository est le plus ancien site de cette sélection. On y retrouve plusieurs centaines de jeux de données open source en langue anglaise. Ils recouvrent des domaines aussi variés que l’informatique, l’ingénierie, les jeux, le droit, les sciences de la vie, les sciences sociales ou encore les sciences physiques. Le site répertorie les sets de données par grandes familles d’algorithmes : classification, régression, clustering… De même, il est possible de filtrer les données par types : image, informations multivariées, séquentielles, tabulaires, textuelles, séries temporelles, etc.
Lancè en 2020 puis acquise en 2017 par Google, Kaggle est une plateforme web popularisée par les compétitions qu’elle héberge autour de défis en data science. Elle met à disposition des centaines de jeux de données open source déployés à l’occasion de ces compétitions. Recouvrant textes, sons et images, ils sont principalement disponibles en langue anglaise. La plateforme offre néanmoins une trentaine de jeux de données en français. Parmi eux, on relève divers référentiels : les codes postaux INSEE, un dictionnaire français ou encore un dictionnaire des noms propres. Certains de ces data sets sont verticaux. C’est le cas notamment d’un jeu de données sur la consommation de gaz et d’électricité en France entre 2011 et 2021 ou encore d’une documentation sur les réglementations environnementales internationales, également en langue française.
Google Dataset Search est l’une des bases de data sets open source les plus riches au monde pour le machine learning et le big data. Le service répertorie au total 25 millions de jeux de données notamment utilisables par des modèles de machine learning. Il se présente sous la forme d’un moteur de recherche où taper sa requête en langage naturel. Google Dataset Search référence l’ensemble des data sets des sites de cette sélection hormis ceux d’AWS, de Data.gouv.fr jusqu’à Kaggle. Il indexe aussi les jeux de données mis à disposition par des universités ou des laboratoires actifs dans la recherche en méga data ou data science. Il permet de filtrer ceux mis à disposition gratuitement.
Sur sa place de marché d’applications, Amazon Web Services (AWS) propose une section répertoriant près de 500 jeux de données. Parmi eux, 220 sont disponibles en open data. Ils recouvrent nombre de domaines : transport public, imagerie satellite, données cliniques pour la recherche pharmaceutique, etc. Très majoritairement en langue anglaise, tous sont compatibles avec le service de stockage Amazon S3 d’AWS.
