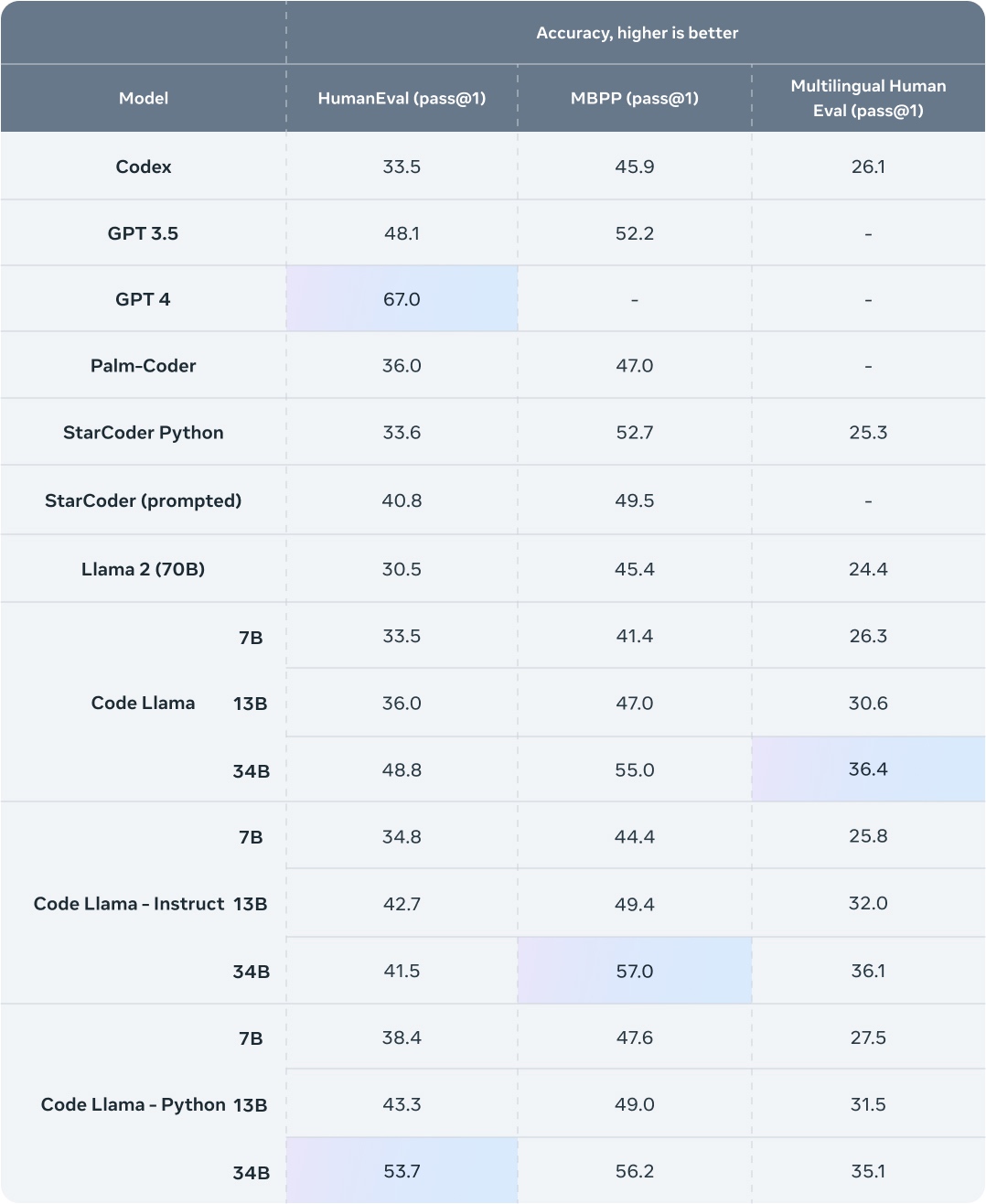
Le groupe META ; mais c’est aussi le cas d’autres entreprises du secteur de l’intelligence artificielle, auraient entraîné leur système d’IA générative sur une base de données piratée, Books3 : voici ce qu’elle contient, selon les investigations de The Atlantic.
Introduction
Une base de données secrète et piratée, des livres d’illustres auteurs comme Stephen King et Margaret Atwood, et un silence plus qu’opaque : voici comment résumer les investigations d’Alex Reisner. Cet informaticien et écrivain, qui relate son enquête dans les colonnes de The Atlantic le 19 août dernier, s’est plongé dans les bases de données d’entraînements des grands modèles de langage. Car si les auteurs se plaignent depuis des mois de voir leurs œuvres servir de données d’entraînements des systèmes d’IA générative comme ChatGPT, Bard ou DALL-E sans leur consentement, ils n’avaient jusqu’à présent pas le moindre accès à ces données. Les entreprises qui développent les outils d’IA générative permettant de générer du texte, des images ou du code, ne sont pour l’instant pas soumises à des obligations de transparence en la matière. Et lorsqu’on les interroge sur le contenu de ces données de formation de leur système, elles restent souvent évasives.
L’auteur explique ainsi être parti d’un constat : pour produire les réponses à des prompts, les systèmes d’IA ont dû ingurgiter des milliards de données en accès libre sur le Web, mais pas seulement. Ils ont dû aussi s’entraîner sur bon nombre de « données plus qualitatives » : des livres, protégés par des droits d’auteur, dont la moindre utilisation devrait nécessiter un consentement de leurs ayants droit. Si l’existence de bibliothèque pirate est relativement connue, son contenu l’est moins.
« La seule façon de répliquer des modèles comme ChatGPT » : Books3
Alex Reisner explique ainsi avoir passé du temps sur les plateformes GitHub et Hugging Face, épluchant des discussions de développeurs universitaires et d’amateurs. Il aurait ensuite téléchargé un cache massif de textes d’entraînement créé par EleutherAI — une organisation à but non lucratif — qui contient l’ensemble de données Books3.
En 2020, Books3 a été mise en ligne par Shawn Presser, un chercheur qui milite pour l’open source. Pour ce dernier, cette base de données est « la seule façon de répliquer des modèles comme ChatGPT ». Sans ce jeu de data, seules des sociétés « d’un milliard de dollars » comme OpenAI auraient suffisamment de ressources pour créer des outils d’IA générative, explique-t-il dans la revue Gizmodo. Cette dernière comprendrait près de 196 640 références au format plain.txt, selon un de ses tweets relayés par Torrent Freak.
170 000 livres publiés ces 20 dernières années
Cette base aurait été utilisée par META pour entraîner son LLaMA pour Large Language Model Meta AI, un modèle open source qui se présente comme une alternative au GPT d’OpenAI, comme l’entreprise l’a elle-même écrit dans un papier de recherche. Cette utilisation est d’ailleurs au cœur d’un procès initié en juillet dernier aux États-Unis, qui oppose l’humoriste américaine Sarah Silverman et deux autres auteurs à Meta et à OpenAI.
Et que contient cette base ?
Elle comporte bon nombre de livres piratés (près de 170 000) dont la majorité a été publiée ces 20 dernières années, ainsi que d’autres données plus surprenantes comme les sous-titres de vidéos sur YouTube, les documents et transcriptions du Parlement européen, Wikipédia en anglais, les courriels envoyés et reçus par les employés d’Enron Corporation avant son effondrement en 2001.
Documentaires, travaux de chercheurs, thrillers, les livres concernés représenteraient pour un tiers de la fiction, et pour deux tiers des documentaires, provenant de grands et petits éditeurs, par exemple Penguin Random House, certainement la plus grandes maisons d’édition américaine. Des livres écrits par Stephen King, Margaret Atwood, Haruki Murakami et bien d’autres auraient donc servi de données d’entraînements pour des programmes d’IA générative.
Du cotè des auteurs français : Quels auteurs français ont alimenté les intelligences artificielles, malgré eux ?
Publié sur Actualitté par Nicolas Gary le 27 septembre 2023