On ne présente plus Google Meet ; le service de visioconférence gratuit de Google !


Google annonce des nouveautés pour Meet
En résumé, les dernières fonctions ajoutées :
- Une interface plus claire
- L’IA pour améliorer la qualité vidéo
- Des arrière-plans vidéo sur le Web et le mobile
- Afficher simultanément plusieurs participants depuis un mobile
- Un outil permettant de surveiller en temps réel l’état du réseau
- Un outil pour surveiller les performances de sa machine
Toutes les informations sur : Official Blog Meet

Google Maps : plein de nouveautés grâce à l’IA
Est-il encore nécessaire de présenter Google Maps ?
Avec plus de 15 ans d’existence, Google Maps a été constamment amélioré. Fidèle à sa tradition, la firme de Mountain View a annoncé, début 2021, une série de nouvelles innovations, permises par ses avancées dans le domaine de l’intelligence artificielle, qui vont encore venir perfectionner le service de cartographie en ligne.
Première nouveauté ; Live View
La principale nouveauté fonctionnalité est le Live View. Basée sur la réalité augmentée, elle permet de se guider à l’intérieur d’un bâtiment. Un outil qui peut s’avérer extrêmement précieux si vous vous perdez dans une gare ou un aéroport, ou encore dans un centre commercial. Dans un billet de blog, Google en a dit plus sur le fonctionnement de cette option :
Dixit Google :
Live View repose sur une technologie que nous appelons localisation globale, qui a recours à l’IA pour analyser des milliards d’images Street View et ainsi comprendre votre orientation.
Grâce à de nouvelles avancées qui nous aident à calculer l’altitude exacte et le placement des objets à l’intérieur d’un bâtiment, nous pouvons désormais proposer Live View dans les endroits où l’on se perd le plus souvent.

Choisir un mode de déplacement le plus écologique sera désormais possible
A ce jour, ce service n’est disponible que dans certains centres commerciaux aux États-Unis à Chicago, Los Angeles, San Francisco, ou encore Seattle. Au cours des prochains mois, il sera déployé dans des villes comme Tokyo et Zurich, avant, on l’espère, une arrivée dans l’Hexagone.
Autres nouveautés à venir
D’autres innovations ont été annoncées par Google, telles que la possibilité de planifier ses sorties en tenant compte de la météo et de la qualité de l’air, à travers une série de calques qui seront présents sur les cartes. Les prévisions météo seront disponibles dans le monde entier prochainement, mais la qualité de l’air ne sera lancée qu’aux Etats-Unis, en Australie et en Inde, dans un premier temps.
Autre nouveauté intéressante : Google développe actuellement un modèle d’itinéraire qui permet d’optimiser sa consommation de carburant « en fonction de facteurs tels que le degré de pente d’une route ou les ralentissements dus aux embouteillages. » La possibilité sera ainsi donnée au conducteur d’opter « par défaut pour l’itinéraire le moins émetteur de CO2 lorsque cet itinéraire donne sensiblement la même heure d’arrivée que l’itinéraire le plus rapide. »
Google ajoute une vue immersive
Baptisée Immersive View, la nouveauté principale est pour l’heure uniquement disponible dans 15 villes dont Paris, New York, Venise et Tokyo, la capitale du Japon. Cette fonctionnalité permet d’accéder à une vision en trois dimensions de son itinéraire à travers une ville, et ce grâce à une intelligence artificielle qui fusionne des « milliards d’images Street View et aériennes ». Désormais, explique Google, « vous pouvez préparer chaque virage comme si vous y étiez grâce à des indications détaillées et visuelles et utiliser le curseur de temps pour planifier le moment de votre départ en fonction d’informations utiles, telles que des simulations de trafic et de conditions météorologiques ».

Deux manières d’optimiser la découverte et la valeur de vos contenus multimédias
Dans un billet de Blog, Google Cloud Video Intelligence présente les avantages de sa méthode.
Allez sur API Cloud Video Intelligence tout est clairement expliqué.

Google veut utiliser l’IA pour mieux gérer les feux de circulation
Un premier test prometteur a déjà été mené en Israël.
Les feux de circulation aident à réguler le trafic sur nos routes, la chose n’est plus à démontrer. Mais cette solution, dans son implémentation actuelle tout du moins, n’est pas nécessairement la plus respectueuse de l’environnement. Que peut-on alors faire ? Lorsque nous patientons à un feu, la voiture reste à l’arrêt tant que celui-ci est rouge. Et le moteur continue de tourner – la plupart du temps – inutilement jusqu’à ce qu’il passe au vert. Ce vieux système peut être amélioré. Google a une idée.
Google utilise l’IA pour optimiser les feux de circulation
Autrement dit, les voitures consomment du carburant pour rien. Ce qui a pour conséquence d’augmenter la pollution. Encore. Cela étant dit, en Israël, Google a décidé de mener une expérimentation dans laquelle le géant américain utilisera l’intelligence artificielle pour tenter de rendre les feux de circulation plus efficients. Cette dernière étudiera et observera les flux de véhicules puis utilisera ces données pour tenter de mieux caler les timers des feux.
Un premier test prometteur a déjà été mené en Israël
Si l’on se réfère au programme pilote qui a été mené en Israël en partenariat avec les municipalités de Haifa, Beer-Sheva et la Israel National Roads Company, la firme de Mountain View affirme qu’en utilisant l’IA, on peut observer une réduction de 10 à 20 % du temps passés aux intersections. Et ceci est tout à fait logique, quand on y réfléchit. En effet, si une voiture pouvait aller d’un point A à un point B sans devoir s’arrêter, la quantité de carburant consommé devrait, en théorie, être moindre.
Bien sûr, si l’on pouvait avoir uniquement des véhicules électriques sur les routes, cela viendrait résoudre tout le problème, mais il faudra attendre de très, très longues années avant qu’il n’existe plus aucune voiture thermique en circulation, si jamais ce jour arrive. Google explique vouloir désormais éprouver ce système à Rio de Janeiro. La firme américaine est par ailleurs en discussion avec plusieurs autres villes dans le monde entier pour aller plus loin.

Après le Machine Learning, Google va utiliser le Deep Learning pour concevoir ses puces.
Depuis le blog de AI.Google :
Advances in machine learning (ML) often come with advances in hardware and computing systems. For example, the growth of ML-based approaches in solving various problems in vision and language has led to the development of application-specific hardware accelerators (e.g., Google TPUs and Edge TPUs). While promising, standard procedures for designing accelerators customized towards a target application require manual effort to devise a reasonably accurate simulator of hardware, followed by performing many time-intensive simulations to optimize the desired objective (e.g., optimizing for low power usage or latency when running a particular application). This involves identifying the right balance between total amount of compute and memory resources and communication bandwidth under various design constraints, such as the requirement to meet an upper bound on chip area usage and peak power. However, designing accelerators that meet these design constraints is often result in infeasible designs. To address these challenges, we ask: “Is it possible to train an expressive deep neural network model on large amounts of existing accelerator data and then use the learned model to architect future generations of specialized accelerators, eliminating the need for computationally expensive hardware simulations?”
Texte complet :Offline Optimization for Architecting Hardware Accelerators

Créez vos propres personnages de manga grâce à cette IA de Google
Google lance en partenariat avec le gouvernement japonais (via le MITI) une nouvelle application appelée « Giga Manga » pour vous permettre de dessiner vos propres manga à l’aide de l’intelligence artificielle.
Rendez-vous sur la page Giga Manga et laissez votre imagination s’exprimer !
Vous pouvez aussi aller vous promener sur Arts and culture by google

Alphabet va utiliser l’IA pour découvrir des médicaments
Alphabet, maison mère de Google, a annoncé jeudi 4 novembre 2021 la création d’Isomorphic Laboratories. Cette nouvelle entreprise s’appuiera sur les travaux effectués par DeepMind, autre filiale d’Alphabet, en matière d’intelligence artificielle. Le but avoué est de découvrir de nouveaux médicaments et “des remèdes à certaines des maladies les plus dévastatrices pour l’humanité”.

Very little was revealed about the company in its debut blog post and a very general accompanying FAQ. The aim of the company is to “build a computational platform to understand biological systems from first principles to discover new ways to treat disease.”
Google crée une nouvelle IA pour lutter contre la désinformation
Trouvé sur le blog officiel de Google France
Comment L’IA protège notre moteur de recherche
L’IA au service de la sécurité des recherches sur Google
Chaque jour, des internautes consultent Google à la recherche d’informations essentielles pour assurer leur sécurité et celle de leur famille. Qu’il s’agisse de mettre en évidence les ressources faisant autorité à la suite d’une catastrophe naturelle ou de fournir des informations sanitaires urgentes, nous cherchons constamment de nouvelles façons de nous assurer que des informations pertinentes sont accessibles en quelques clics. Les progrès en matière d’Intelligence Artificielle (IA) permettent le développement de nouvelles techniques, comme la prévision des inondations, pour aider la population à se protéger.Voici un aperçu des dernières méthodes utilisées par les systèmes d’IA les plus avancés pour nous aider à orienter les internautes vers des sources d’aide essentielles, tout en évitant l’exposition à des contenus potentiellement choquants ou dangereux, pour qu’ils restent en sécurité, que ce soit en ligne ou dans le monde réel.
Trouver des informations fiables et utiles quand vous en avez le plus besoin
Nous savons que les internautes utilisent notre moteur de recherche pour trouver des informations fiables dans les moments les plus critiques. Aujourd’hui, si un utilisateur effectue une recherche Google concernant le suicide, les agressions sexuelles, la toxicomanie et la violence domestique, il voit s’afficher, non seulement des résultats dignes de confiance, mais aussi les lignes d’écoute pertinentes.Cependant, les personnes en situation de crise personnelle peuvent effectuer leurs recherches de différentes manières et il n’est pas toujours évident d’identifier leurs besoins réels. Pour coder nos systèmes de manière à ce qu’ils affichent les résultats de recherche les plus utiles, nous devons être en mesure de déterminer les attentes de l’utilisateur avec précision. Dans ces cas-là, pour mieux comprendre le langage, le recours à l’apprentissage automatique est particulièrement utile et important.Notre dernier modèle d’IA, MUM, nous permet de détecter automatiquement – et avec plus de précision – un éventail plus vaste de recherches liées à des situations de crise personnelle. MUM est en mesure de mieux comprendre les intentions qui peuvent se cacher derrière certaines requêtes effectuées sur le moteur de recherche. Il peut ainsi détecter si un utilisateur a besoin d’aide. Cela nous permet d’afficher de manière plus efficace des informations fiables et utiles au bon moment. Nous commencerons à utiliser MUM pour mettre en œuvre ces améliorations dans les semaines à venir.
Éviter les contenus explicites non souhaités
Pour assurer la sécurité des utilisateurs de notre moteur de recherche, nous devons également éviter de les exposer à des contenus indésirables. En effet, les internautes doivent pouvoir effectuer leurs recherches en toute sérénité. Cela est parfois difficile, car il arrive aux créateurs de contenu d’utiliser des termes anodins pour désigner un contenu explicite ou suggestif. Ainsi, le principal type de contenu correspondant pour votre requête ne sera peut-être pas ce que vous vouliez trouver. Dans ce cas, il pourrait s’avérer que la majorité des résultats d’une recherche soient de nature explicite, quand bien même cela ne corresponde pas aux recherches de l’utilisateur. SafeSearch est l’une des solutions que nous proposons pour contrer ce phénomène. Cet outil permet de filtrer les résultats de recherche explicites ; il est d’ailleurs sélectionné par défaut sur les comptes des utilisateurs de moins de 18 ans. En outre, même si SafeSearch est désactivé, nos systèmes limitent la part de résultats explicites pour les recherches qui ne s’y prêtent pas. Au total, nos algorithmes améliorent la sécurité de centaines de millions de recherches à travers le monde, qu’il s’agisse d’informations, d’images ou de vidéos. Mais nous pouvons faire encore mieux. Par exemple, nous utilisons des techniques d’IA avancées, telles que BERT, pour mieux comprendre les résultats attendus et réduire sensiblement la part de résultats explicites non souhaités.La sécurité des recherches est une question complexe que nous étudions depuis longtemps ; ne serait-ce que l’année dernière, BERT nous a permis de réduire de 30 % la proportion de résultats de recherche explicites inattendus. Les conséquences sont d’autant plus manifestes pour les recherches ayant trait aux questions d’appartenance ethnique, d’orientation sexuelle et d’identité de genre, qui touchent principalement les femmes, en particulier les femmes issues de minorités visibles.
Déployer nos protections dans le monde entier
MUM est capable de mobiliser des connaissances dans les 75 langues pour lesquelles le modèle est formé, ce qui nous permet de déployer nos mesures de protection dans le monde entier de manière bien plus efficace. Ainsi, lorsque nous entraînons MUM en vue d’effectuer une tâche donnée, notamment la classification de la nature d’une recherche, le modèle apprend à le faire dans toutes les langues qu’il connaît. Nous utilisons donc l’IA, notamment pour limiter la présence de pages de spams inutiles, voire dangereuses, dans vos résultats de recherche. Au cours des prochains mois, grâce à MUM, nous pourrons améliorer la protection contre ces spams et inclure des langues pour lesquelles nous avons peu de données d’apprentissage automatique. Nous serons également en mesure de mieux détecter les recherches relatives à des situations de crise personnelle partout dans le monde et, grâce à nos partenaires locaux, d’afficher des informations pertinentes dans de nouveaux pays. Comme pour toute amélioration de notre moteur de recherche, ces nouveautés seront soumises à un processus d’évaluation rigoureux, qui tient compte des retours de nos évaluateurs dans le monde entier, afin de nous assurer que nous proposons des résultats plus pertinents et plus utiles. Quelles que soient les recherches effectuées par nos utilisateurs, nous sommes là pour les aider à trouver des réponses en toute sécurité.
Texte complet : Comment L’IA protège notre moteur de recherche Publié le 30 mars 2022

Une IA Google réalise des retouches photo plus vraies que nature
Total Relighting: Learning to Relight Portraits for Background Replacement
We propose a novel system for portrait relighting and background replacement, which maintains high-frequency boundary details and accurately synthesizes the subject’s appearance as lit by novel illumination, thereby producing realistic composite images for any desired scene. Our technique includes foreground estimation via alpha matting, relighting, and compositing. We demonstrate that each of these stages can be tackled in a sequential pipeline without the use of priors (e.g. known background or known illumination) and with no specialized acquisition techniques, using only a single RGB portrait image and a novel, target HDR lighting environment as inputs. We train our model using relit portraits of subjects captured in a light stage computational illumination system, which records multiple lighting conditions, high quality geometry, and accurate alpha mattes. To perform realistic relighting for compositing, we introduce a novel per-pixel lighting representation in a deep learning framework, which explicitly models the diffuse and the specular components of appearance, producing relit portraits with convincingly rendered non-Lambertian effects like specular highlights. Multiple experiments and comparisons show the effectiveness of the proposed approach when applied to in-the-wild images.
Depuis le Blog Google :
Total Relighting: Learning to Relight Portraits for Background Replacement
Nous proposons un nouveau système pour le ré-éclairage de portraits et le remplacement de l’arrière-plan, qui conserve les détails des limites à haute fréquence et synthétise avec précision l’apparence du sujet tel qu’il est éclairé par un nouvel éclairage, produisant ainsi des images composites réalistes pour toute scène souhaitée. Notre technique comprend l’estimation de l’avant-plan via le matage alpha, le ré-éclairage et le compositing. Nous démontrons que chacune de ces étapes peut être abordée dans un pipeline séquentiel sans l’utilisation d’antécédents (par exemple, un arrière-plan ou un éclairage connus) et sans techniques d’acquisition spécialisées, en utilisant seulement une seule image de portrait RVB et un nouvel environnement d’éclairage HDR cible comme entrées. Nous entraînons notre modèle à l’aide de portraits relit de sujets capturés dans un système d’illumination computationnel de type scène de lumière, qui enregistre des conditions d’éclairage multiples, une géométrie de haute qualité et des mattes alpha précises. Afin de réaliser un relighting réaliste pour le compositing, nous introduisons une nouvelle représentation de l’éclairage par pixel dans un cadre d’apprentissage profond, qui modélise explicitement les composantes diffuses et spéculaires de l’apparence, produisant des portraits relit avec des effets non-lambertiens convaincants tels que les reflets spéculaires. De multiples expériences et comparaisons montrent l’efficacité de l’approche proposée lorsqu’elle est appliquée à des images dans la nature.
L’IA en renfort des vieilles techniques
L’ensemble tient en deux mots : neural net.
C’est un système basé sur l’intelligence artificielle qui va passer l’image à la moulinette. Il va en tirer ce qu’on appelle une carte normale. C’est un concept omniprésent en 3D : grâce à une image un peu spéciale, on peut définir pour chaque point d’une autre image (par exemple, la texture d’un personnage de jeu vidéo) la perpendiculaire (normale) à la surface, et donc l’angle auquel celle-ci reflète la lumière. Ici, c’est la même idée, sauf que leur algorithme basé sur l’IA calcule cette carte normale sans objet 3D. Il le fait directement à partir de l’image pour simuler le volume de la personne au premier plan, comme s’il était présent en trois dimensions. À partir de ces données, l’algorithme peut recalculer la nouvelle couleur de chaque point pour fournir l’image finale.
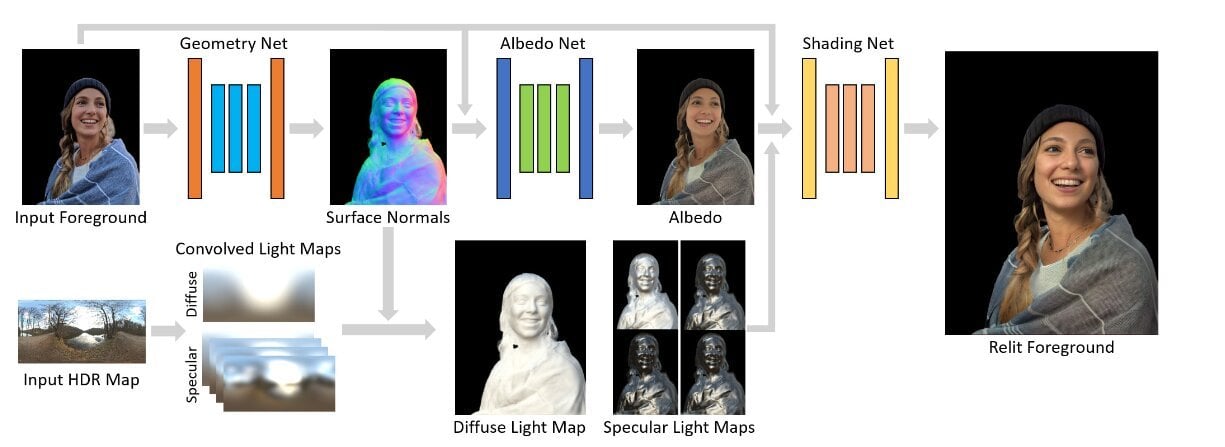
On imagine aisément l’intérêt d’un tel outil, dans l’ensemble de l’industrie graphique digitale. Par exemple, cela pourrait grandement faciliter la vie des artistes digitaux qui réalisent des effets spéciaux, qui se battent avec la lumière au quotidien. Avec un tel outil, il suffit de traiter les images en question avec un algorithme de ce genre. Bien plus facile que les techniques traditionnelles, qui impliquent de passer un temps fou à recréer des modèles 3D pour reconstituer un éclairage cohérent qu’il faut ensuite recomposer dans la scène.

Google vient de lancer un jeu de flipper universel jouable sur toutes les plates-formes depuis un simple navigateur Web
Un peu de fun dans ce monde de brutes …
Google vous propose de jouer au flipper sur n’importe quelle plateforme sur un navigateur Web : Pinball

IMAGEN une IA incroyable de Google qui transforme du texte en image
Google Research, Brain Team present
We present Imagen, a text-to-image diffusion model with an unprecedented degree of photorealism and a deep level of language understanding. Imagen builds on the power of large transformer language models in understanding text and hinges on the strength of diffusion models in high-fidelity image generation.
Our key discovery is that generic large language models (e.g. T5), pretrained on text-only corpora, are surprisingly effective at encoding text for image synthesis: increasing the size of the language model in Imagen boosts both sample fidelity and image-text alignment much more than increasing the size of the image diffusion model. Imagen achieves a new state-of-the-art FID score of 7.27 on the COCO dataset, without ever training on COCO, and human raters find Imagen samples to be on par with the COCO data itself in image-text alignment.
To assess text-to-image models in greater depth, we introduce DrawBench, a comprehensive and challenging benchmark for text-to-image models. With DrawBench, we compare Imagen with recent methods including VQ-GAN+CLIP, Latent Diffusion Models, and DALL-E 2, and find that human raters prefer Imagen over other models in side-by-side comparisons, both in terms of sample quality and image-text alignment.
Nous présentons Imagen, un modèle de diffusion texte-image avec un degré de photoréalisme sans précédent et un niveau profond de compréhension du langage. Imagen s’appuie sur la puissance des grands modèles de langage transformateurs pour la compréhension du texte et sur la force des modèles de diffusion pour la génération d’images haute-fidélité. Notre principale découverte est que les grands modèles de langage génériques (par exemple T5), pré-entraînés sur des corpus de texte uniquement, sont étonnamment efficaces pour coder le texte pour la synthèse d’images : l’augmentation de la taille du modèle de langage dans Imagen améliore à la fois la fidélité de l’échantillon et l’alignement image-texte beaucoup plus que l’augmentation de la taille du modèle de diffusion d’image. Imagen obtient un nouveau score FID de pointe de 7,27 sur le jeu de données COCO, sans jamais s’entraîner sur COCO, et les évaluateurs humains trouvent que les échantillons d’Imagen sont équivalents aux données COCO elles-mêmes en matière d’alignement image-texte. Pour évaluer les modèles texte-image de manière plus approfondie, nous présentons DrawBench, une référence complète et stimulante pour les modèles texte-image. Grâce à DrawBench, nous comparons Imagen à des méthodes récentes, notamment VQ-GAN+CLIP, les modèles de diffusion latente et DALL-E 2, et nous constatons que les évaluateurs humains préfèrent Imagen aux autres modèles dans les comparaisons côte à côte, tant en termes de qualité des échantillons que d’alignement image-texte.
Il y a une nouvelle tendance en vogue dans le domaine de l’intelligence artificielle : les générateurs de texte en image.
Alimentez ces programmes avec le texte de votre choix et ils généreront des images remarquablement précises, à l’instar d’Imagen, récemment dévoilée par Google.
Quelques exemples :
A photo of a raccoon wearing an astronaut helmet, looking out of the window at night.
A transparent sculpture of a glass duck. The sculpture is in front of a painting of a landscape.
A giant corn cobra in a farm


Bien évidemment, le texte à colorié doit être en anglais.
Exemple de la démarche à suivre :
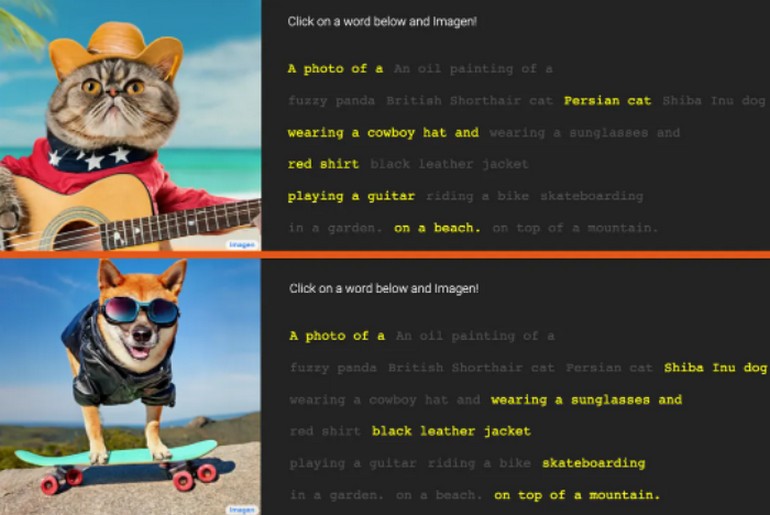
Les papiers techniques sont disponible par des liens sur le site Imagen.
Vous pouvez aussi regarder la vidéo BFM :
Imagen, l’IA de Google qui transorfme le texte en image
Sur la droite une vidéo sur ce sujet :
This AI is INSANELY good at creating what you IMAGEN!!
DALL-E peut désormais être intégré dans les applications et arrive sur les smartphones !
Publié sur Presse Citron par Jean-Yves Alric le 7 novembre 2022
Sur Arte : L’œuvre et intelligence artificielle
Google vous laisse jouer avec le son et le temps sur Playground
Google announced I/O 2022 with an SVD puzzle revealing the conference dates, and it’s now ending it with Playground, a “sound toy” that lets you “create your own Euclidean rhythms and melodies” : Binary, music theory, tennis: How to solve the Google I/O 2022 teaser puzzle
Google a annoncé l’I/O 2022 avec un puzzle SVD révélant les dates de la conférence, et il la termine maintenant avec Playground, un « jouet sonore » qui vous permet de « créer vos propres rythmes et mélodies euclidiennes » : Binary, music theory, tennis: How to solve the Google I/O 2022 teaser puzzle
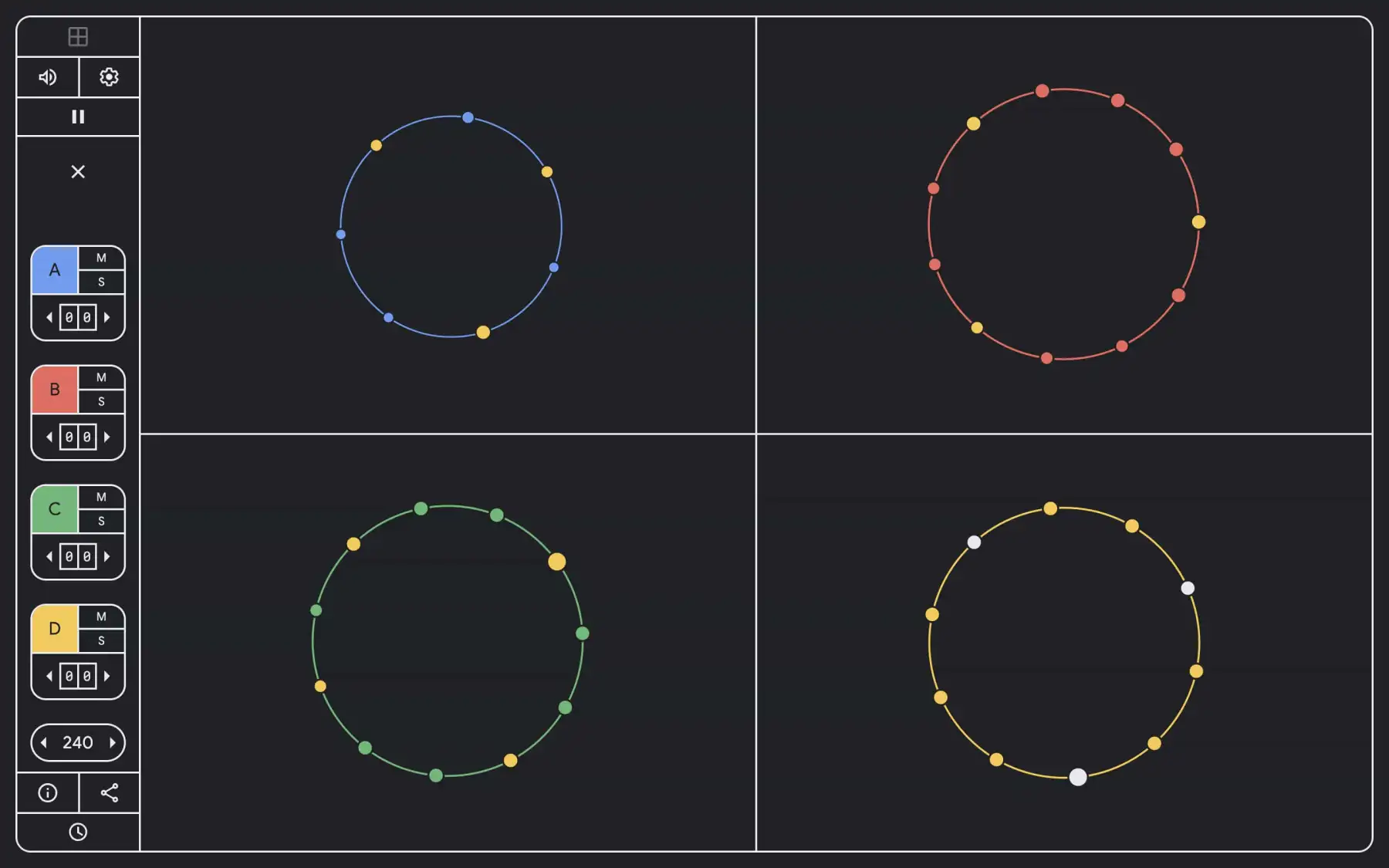
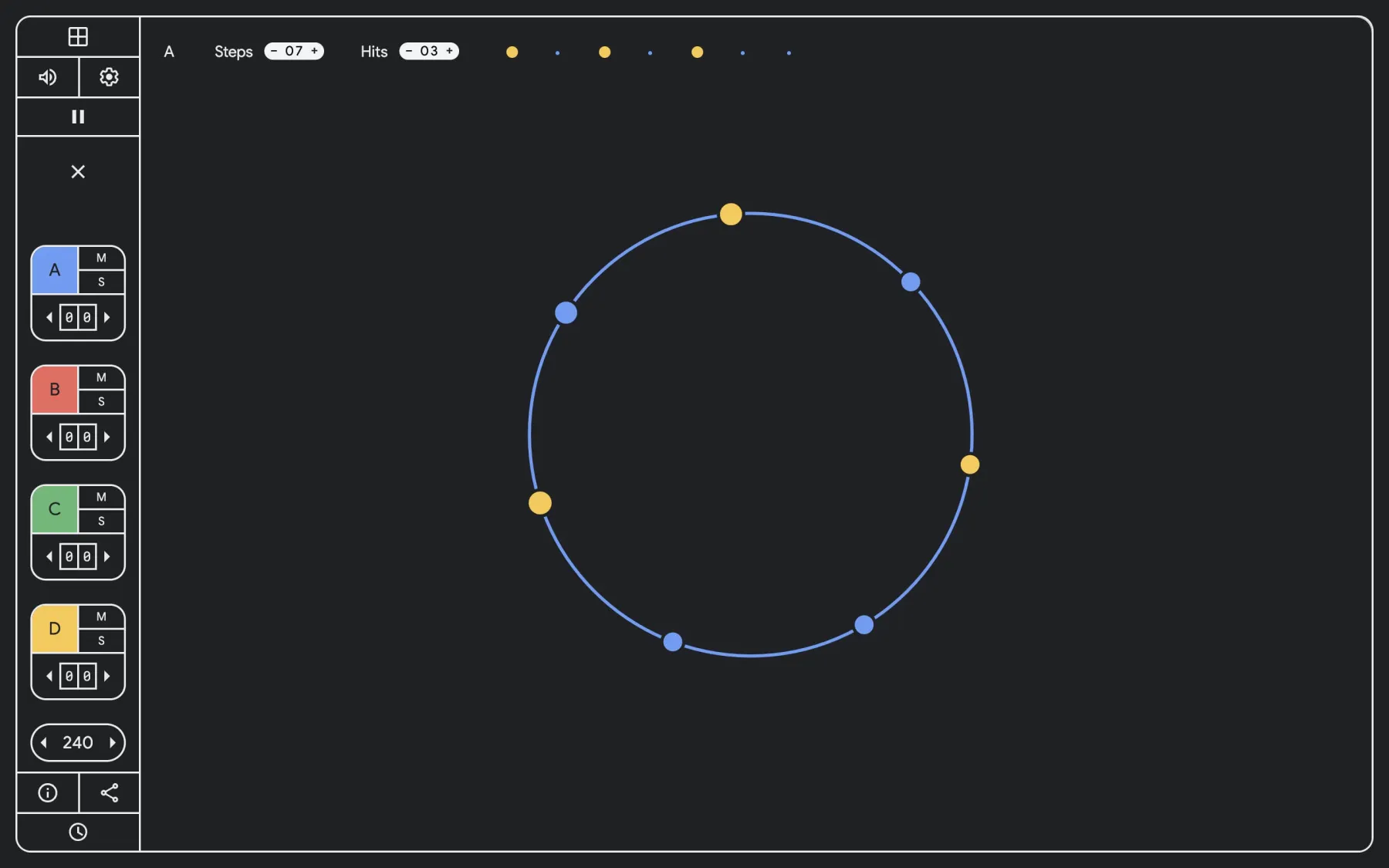
Playground is nearly identical to the I/O 2022 puzzle version, and this toy is “brought to you by Google Developers.” The UI is responsive and quite mobile-friendly for on-the-go beat making. It involves you “choosing the total number of steps and hits for each sequencer,” while the accompanying circular graphics look great projected.
- Euclidean rhythms evenly distribute hits and silences across the entire length.
- For every hit, you can also select one of four available pitches.
- When multiple Euclidean rhythms are layered, they create polyrhythms that can be manipulated by adjusting the offset, or starting position, of each sequencer.
Playground est presque identique à la version puzzle de la I/O 2022, et ce jouet est « apporté à vous par les développeurs de Google ». L’interface utilisateur est réactive et tout à fait adaptée au mobile pour le beat making en déplacement. Vous devez « choisir le nombre total d’étapes et de coups pour chaque séquenceur », tandis que les graphiques circulaires qui l’accompagnent sont très bien projetés.
- Les rythmes euclidiens répartissent uniformément les hits et les silences sur toute la longueur.
- Pour chaque coup, vous pouvez également sélectionner l’une des quatre hauteurs disponibles.
- Lorsque plusieurs rythmes euclidiens sont superposés, ils créent des polyrythmes qui peuvent être manipulés en ajustant le décalage, ou la position de départ, de chaque séquenceur.
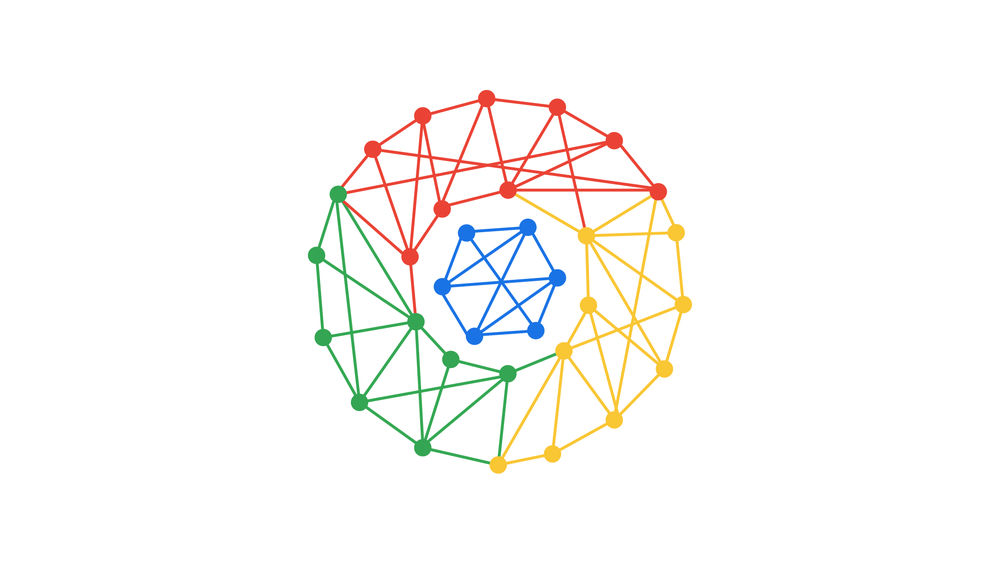
In addition to the Playground sound toy, there’s also I/O 2022’s Euclidean Clock (as seen in the cover image above).
This clock uses Euclidean rhythms to represent today’s date and time. Listen to the harmony of all four loops together, or try muting one or more to focus in on a rhythm.
From the outside, it’s the date, hours, minutes, and seconds represented by dots. Be sure to unmute from the control strip to literally hear the time.
En plus du jouet sonore Playground, il y a aussi l’horloge euclidienne d’I/O 2022 (comme on peut le voir sur l’image de couverture ci-dessus).
Cette horloge utilise des rythmes euclidiens pour représenter la date et l’heure du jour. Écoutez l’harmonie des quatre boucles ensemble, ou essayez d’en couper une ou plusieurs pour vous concentrer sur un rythme.
De l’extérieur, il s’agit de la date, des heures, des minutes et des secondes représentées par des points. Assurez-vous de désactiver le son à partir de la bande de contrôle pour entendre littéralement l’heure.

Building a more helpful browser with machine learning
Comment Google utilise le machine learning pour améliorer Chrome
At Google we use technologies like machine learning (ML) to build more useful products — from filtering out email spam, to keeping maps up to date, to offering more relevant search results. Chrome is no exception: We use ML to make web images more accessible to people who are blind or have low vision, and we also generate real-time captions for online videos, in service of people in noisy environments, and those who are hard of hearing.
This work in Chrome continues, so we wanted to share some recent and future ML improvements that offer a safer, more accessible and more personalized browsing experience. Importantly: these updates are powered by on-device ML models, which means your data stays private, and never leaves your device.
More peace of mind, less annoying prompts
Safe Browsing in Chrome helps protect billions of devices every day, by showing warnings when people try to navigate to dangerous sites or download dangerous files (see the big red example below). Starting in March of this year, we rolled out a new ML model that identifies 2.5 times more potentially malicious sites and phishing attacks as the previous model – resulting in a safer and more secure web.
To further improve the browsing experience, we’re also evolving how people interact with web notifications. On the one hand, page notifications help deliver updates from sites you care about; on the other hand, notification permission prompts can become a nuisance. To help people browse the web with minimal interruption, Chrome predicts when permission prompts are unlikely to be granted based on how the user previously interacted with similar permission prompts, and silences these undesired prompts. In the next release of Chrome, we’re launching an ML model that makes these predictions entirely on-device.
Source et suite : Building a more helpful browser with machine learning
Blog Google le 9 juin 2022
Chez Google, nous utilisons des technologies telles que l’apprentissage automatique (ML) pour créer des produits plus utiles, qu’il s’agisse de filtrer les spams, de tenir les cartes à jour ou de proposer des résultats de recherche plus pertinents. Chrome ne fait pas exception à la règle : Nous utilisons l’apprentissage automatique pour rendre les images Web plus accessibles aux personnes aveugles ou malvoyantes, et nous générons également des légendes en temps réel pour les vidéos en ligne, au service des personnes vivant dans des environnements bruyants et des malentendants.
Ce travail dans Chrome se poursuit, et nous voulions donc partager certaines améliorations récentes et futures de ML qui offrent une expérience de navigation plus sûre, plus accessible et plus personnalisée. Important : ces mises à jour sont alimentées par des modèles ML intégrés à l’appareil, ce qui signifie que vos données restent privées et ne quittent jamais votre appareil.
La navigation sécurisée dans Chrome contribue à protéger des milliards d’appareils chaque jour, en affichant des avertissements lorsque des personnes tentent de naviguer vers des sites dangereux ou de télécharger des fichiers dangereux (voir le gros exemple rouge ci-dessous). À partir de mars de cette année, nous avons déployé un nouveau modèle ML qui identifie 2,5 fois plus de sites potentiellement malveillants et d’attaques de phishing que le modèle précédent – ce qui permet d’avoir un web plus sûr et plus sécurisé.
Pour améliorer encore l’expérience de navigation, nous faisons également évoluer la façon dont les gens interagissent avec les notifications Web. D’une part, les notifications de pages permettent d’obtenir des mises à jour des sites qui vous intéressent ; d’autre part, les demandes d’autorisation de notification peuvent devenir une nuisance. Pour aider les utilisateurs à naviguer sur le Web avec un minimum d’interruption, Chrome prédit quand les invites d’autorisation sont susceptibles d’être accordées en fonction de la façon dont l’utilisateur a précédemment interagi avec des invites d’autorisation similaires, et fait taire ces invites indésirables. Dans la prochaine version de Chrome, nous lancerons un modèle ML qui fera ces prédictions entièrement sur l’appareil.

Pour vous : 10 anecdotes que vous ne connaissiez peut-être pas
Le nom Google est une erreur
À l’origine Google ne devait pas s’appeler Google. Les deux fondateurs de l’entreprise voulaient l’appeler Googol (Gogol en français), un terme mathématique désignant un 1 suivi de 100 zéros.
Selon la légende, le nom Google serait la conséquence d’une faute d’orthographe lors de l’enregistrement de l’entreprise.
Le premier serveur était fait de… cube Lego
En 1996, lorsqu’ils travaillaient sur leur moteur de recherche, Larry Page et Sergei Brin, alors étudiants, avaient peu de moyens. Pour créer leur premier serveur, ils ont empilé des disques durs en les séparant avec… des biques Lego.
À l’époque, le serveur contenait 10 disques de 4 Go soit 40 Go. Si cette capacité de stockage semble minuscule aujourd’hui, elle était énorme à l’époque. Aujourd’hui, ce premier serveur haut en couleurs est exposé à l’université de Stanford, là où tout a commencé.
D’ailleurs, vous remarquerez sans doute des similarités entre ce serveur coloré et le logo de Google. Drôle de coïncidence non ?
Google parle aux extraterrestres
Chez Google, on est persuadé que les extra-terrestres ne sont pas loin. Ou qu’ils font des recherches sur le moteur de recherche. En effet, les ingénieurs ont traduit la page d’accueil en 80 langues dont le Klingon, une langue extra-terrestre inventée dans la saga Star Trek.
Google aime les chiens
Chez Google, les chiens sont les bienvenus. Attention, l’entreprise a tout de même quelques exigences. Les chiens des employés peuvent les accompagner au bureau à condition qu’ils maîtrisent leur vessie et aient un comportement amical.
En revanche, nos amis les chats doivent rester seuls à la maison (ils adorent ça non ?). Google n’a rien contre les « ronrons » mais préfère éviter de semer la zizanie dans les bureaux. Puisqu’il y a des chiens, mieux vaut éviter les chats.
Google emploie des chèvres
Non, on ne parle pas des ingénieurs de l’entreprise qui sont tous de vrais cadors dans leurs domaines. Google emploie bien des chèvres. Mais pourquoi ?
Tout simplement pour entretenir les pelouses de son siège social situé à Mountain View, aux abords de San Francisco. L’entreprise ne souhaitait pas avoir recours à des tondeuses à gazon, elle utilise donc 200 chèvres régulièrement pour ses espaces verts.
Google a son propre dinosaure
Si vous avez un jour la chance de vous rendre sur le campus de Google en Californie, vous croiserez sans doute Stan. Il ne s’agit pas du jardinier mais bien d’un dinosaure grandeur nature.
Plus exactement, il s’agit d’un squelette de tyrannosaure. Et puisque chez Google on a beaucoup d’humour, Stan revêt des bijoux et vêtements géants, histoire d’affirmer son style.
Le dinosaure perso de Google a coûté 100 000 dollars à l’entreprise.
Achat d’une entreprise par semaine
Entre 2010 et 2015, Google rachetait en moyenne une entreprise par semaine. Un rythme à peine croyable qui a permis au groupe de grandir rapidement. Grâce à ces rachats, Google a soit récupéré des technologies ou un savoir-faire, soit éliminé des concurrents.
En parallèle, sa branche Google Ventures investissait dans d’autres entreprises pour prendre part à leur capital. Le record absolu d’investissements s’élève à 257,79 millions de dollars et date d’août 2013. L’entreprise qui a bénéficié de ces fonds, vous la connaissez très bien puisqu’il s’agit d’Uber.
L’achat de Youtube dans un… Denny’s
Lorsque l’on parle de rachats historiques, on s’imagine une armée d’avocats, de juristes et de financiers réunis dans une grande salle. Pour le cas du rachat de Youtube par Alphabet (maison-mère de Google), le cadre est bien plus insolite.
En 2006, ce rachat a coûté 1,65 milliard de dollars à Alphabet. Et malgré des enjeux colossaux, les négociations se sont faites aux yeux de tous, dans un Denny’s, un fast-food de Palo Alto. C’est donc dans un diner que Steve Cheng, l’un des fondateurs de Youtube, et les dirigeants de Google ont conclu leur deal.
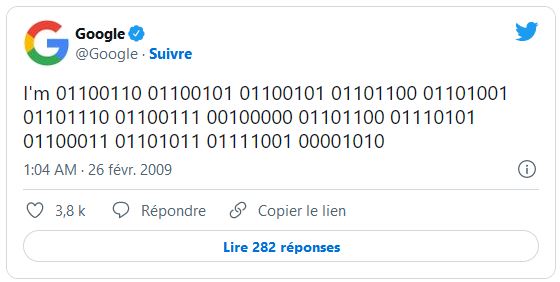
Le premier tweet de Google
« I’m 01100110 01100101 01100101 01101100 01101001 01101110 01100111 00100000 01101100 01110101 01101100 01101001 0110111 0110111 0110111 0110111 0110111 0110111 0110111 0110111 ».
Voilà le premier tweet publié par Google !
Posté en 2009, ce tweet posté en langage binaire signifie « I feel Lucky » soit « J’ai de la chance » en français, terme que l’on retrouvait sous la barre de recherche de Google.
Chez Google, on mange à sa faim
Aux Etats-Unis, on aime manger. Souvent. Très souvent.
Chez Google, on a donc résolu ce problème qui pourrait nuire à la productivité.
Dans l’entreprise, chaque bureau est situé obligatoirement à moins de 46 mètres d’un point de restauration. Qu’il s’agisse de snacks, de boissons ou de vrais repas, il y en a partout et pour tous les goûts. Et bien évidemment, tout est entièrement gratuit pour les employés.


L’IA de Google Photo accuse un utilisateur de pédocriminalité par erreur et le dénonce à la police
Google AI flagged parents’ accounts for potential abuse over nude photos of their sick kids
Un outil de Google dédié à l’automatisation de l’interception d’images à caractère pédocriminel circulant sur le web a semé la zizanie, déclenchant à nouveau la polémique autour du géant et de ses pratiques jugées intrusives en matière de traitement des données personnelles.
L’IA confond domaine médical et pédocriminalité
L’incident s’est produit Outre-Atlantique en février 2021, durant les restrictions liées au Covid-19. Il a été demandé à Mark, un père de famille ayant remarqué un gonflement dans la région génitale de son enfant, de transmettre des photos du problème au cabinet médical avant la tenue de la consultation avec un médecin par visioconférence. Deux jours après celle-ci, Mark reçoit une notification de la part de Google. Celle-ci stipule que ses comptes liés aux services du géant ont été suspendus en raison d’un « contenu préjudiciable » représentant « une violation grave des politiques de Google et qui pourrait être illégal ».
Des pratiques préventives jugées intrusives
Bien que la protection des enfants contre les abus soit primordiale, la question de l’empiétement sur la vie privée se pose auprès de tous les utilisateurs n’ayant rien à se reprocher. Jon Callas, directeur des projets technologiques à l’Electronic Frontier Foundation a par ailleurs réagi auprès du New York Times en qualifiant d’intrusives ces pratiques menées par Google : « C’est précisément le cauchemar qui nous préoccupe tous ».
À ce sujet, Google déclare ne scanner les images de ses utilisateurs que lorsqu’ils utilisent certains services. Dans ce cas de figure, il peut s’agir de la sauvegarde sur Google Photos. Il est d’ailleurs intéressant de rappeler que Google est légalement tenu de signaler toute image de ce type aux autorités. En 2021, pas moins de 621 583 cas ont été rapportés.
Trois sources pour plus de compréhension
- Google AI flagged parents’ accounts for potential abuse over nude photos of their sick kids
Publié sur The Verge le 22 août 2022 par Emma Roth et Richard Lawler - L’IA de Google Photo accuse un utilisateur de pédocriminalité par erreur (et le dénonce à la police)
Publié sur Clubic le 22 août 2022 par Florent Lanne - Google accuse deux papas de pédopornographie, pour avoir pris des photos de leur enfant nu pour le pédiatre
Publié sur Le Figaro Tech et Web le 22 août 2022 par Louis Madelaine
